
Speech-to-Text (STT) technology has transformed the way we interact with devices and applications. From voice-activated assistants like Siri and Alexa to real-time transcription services, STT has become an integral part of our digital ecosystem. It allows machines to process and understand human speech, converting spoken language into written text. Whether it’s enabling hands-free operation of devices or assisting in accessibility for those with disabilities, the applications of STT are vast and rapidly evolving.
But have you ever wondered how this remarkable technology works? How does a model “listen” to human speech and accurately translate it into text? In this comprehensive guide, we will explore the underlying principles of building a custom Speech-to-Text model from scratch. We will break down the process into essential components—from capturing and processing audio, to feature extraction and model training, all the way to final text prediction.
By the end of this guide, you’ll not only understand the intricate journey from spoken language to readable text, but you’ll also be equipped to build your own Speech-to-Text model from the ground up. Whether you’re a developer, a researcher, or simply curious about how this technology works, this guide will give you the knowledge and tools to bring your ideas to life. So, let’s dive in and explore the fascinating world of Speech-to-Text technology!
What is a Speech-to-Text Model?
A Speech-to-Text model converts spoken language into written text. This process involves several complex stages, including audio processing, feature extraction, and model prediction. Imagine a model that listens to a recording and accurately transcribes it into text—this is the essence of STT technology.
Inspired by Human Communication:
Just as our brains convert sounds into meaningful language, STT models mimic this process. Initially, the model identifies basic sound patterns, then progressively understands more complex language structures. This layered approach enables the model to translate spoken words into coherent text effectively.
Why Not Use Basic Audio Processing?
While traditional audio processing techniques can convert sound into text, they often fall short in terms of accuracy and context understanding. Here’s why Speech-to-Text (STT) models are far more effective, illustrated through a real-world example:
Imagine this scenario:
You’re building a voice-activated assistant for an international audience. Let’s follow the journey of two phrases spoken in different contexts: “I need a key to unlock the door” and “That was the key moment in the match.”
- Complexity of Speech Patterns:
Traditional audio processing systems might focus only on basic features like volume, pitch, or frequency. In noisy environments or when spoken with an accent, the system might struggle to even identify individual words. If the speaker has a strong accent or slight variations in pronunciation, it could misinterpret the word “key” as something phonetically similar, like “tea” or “bee.”
On the other hand, an STT model is designed to handle these complexities. It can recognize subtle variations in speech, accents, and pronunciations. Whether the user pronounces “key” with an American or British accent, the STT model accurately transcribes the word while maintaining context.
- Context Understanding:
Basic audio processing lacks the ability to understand context. In both sentences, the word “key” is used, but the meaning differs. A traditional system might fail to distinguish whether “key” refers to a physical object or a metaphorical moment, leading to errors in transcription.
However, an STT model equipped with advanced techniques like Recurrent Neural Networks (RNNs) or Transformers takes context into account. In the first sentence, “I need a key to unlock the door,” the surrounding words—such as “unlock” and “door”—guide the model to deduce that “key” refers to the object. In the second sentence, “That was the key moment in the match,” words like “moment” and “match” help the model understand that “key” is being used metaphorically to describe something crucial.
- Adaptability:
A traditional audio processing system might struggle with context shifts, such as changes in language or meaning. For example, if a speaker says, “I need a key” and then switches to “This key decision shaped the project,” the system might not adapt to the change in meaning.
On the other hand, an STT model can dynamically adjust to these shifts in context. It is trained on large datasets that include diverse language structures and meanings. The model adapts seamlessly, recognizing the different uses of “key” based on the sentence’s overall structure, thereby ensuring higher transcription accuracy even when context varies.
Components of an STT Model
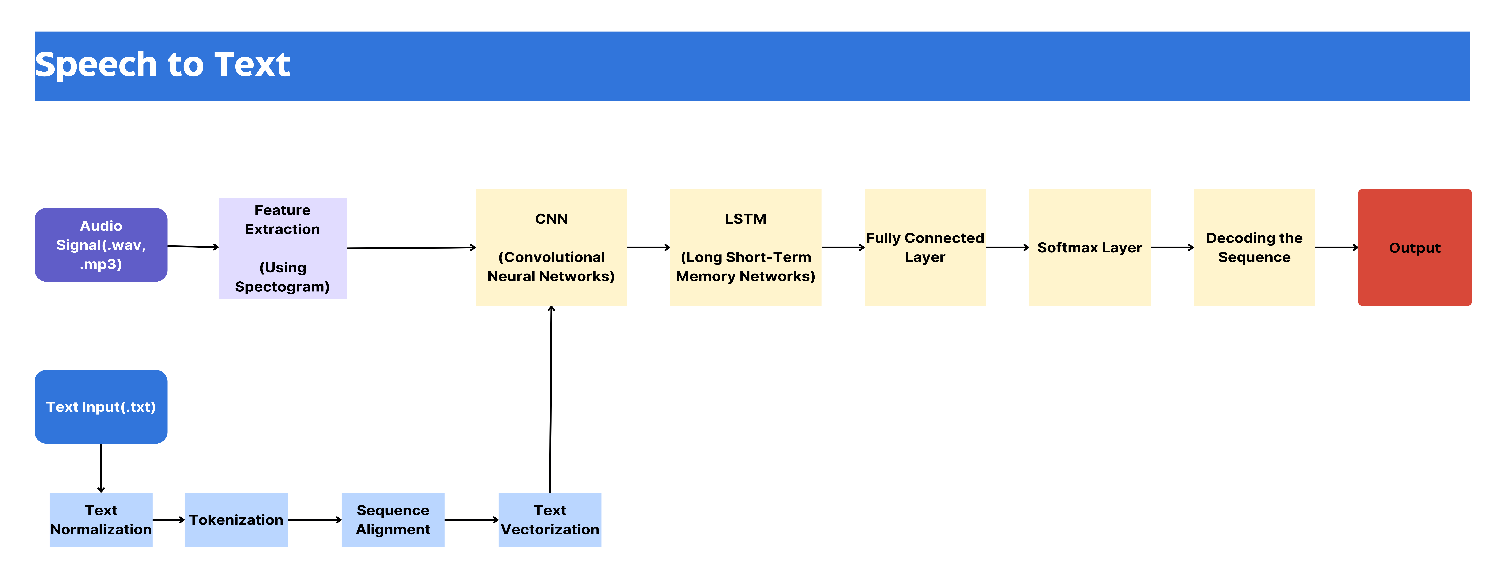
A Speech-to-Text (STT) model is composed of several key components, each playing a vital role in converting spoken language into written text. Below, we’ll explore these components step-by-step, offering examples to make the process easier to understand.
Audio Input
- Overview: The process begins with capturing spoken language. Audio input can be obtained from various sources such as microphones, audio files, or streaming services. Common formats for these files include WAV, MP3, or FLAC.
- Example: Suppose you have a WAV file containing a sentence spoken by a person. This audio is sampled at a specific rate, such as 16 kHz, meaning 16,000 samples of the audio are captured per second.
Feature Extraction
- Overview: Audio signals are complex and consist of various frequencies and amplitudes. To make these signals understandable for a machine learning model, we need to convert them into a set of features. Common techniques include Mel-frequency cepstral coefficients (MFCCs), spectrograms, and mel-spectrograms.
- Example:
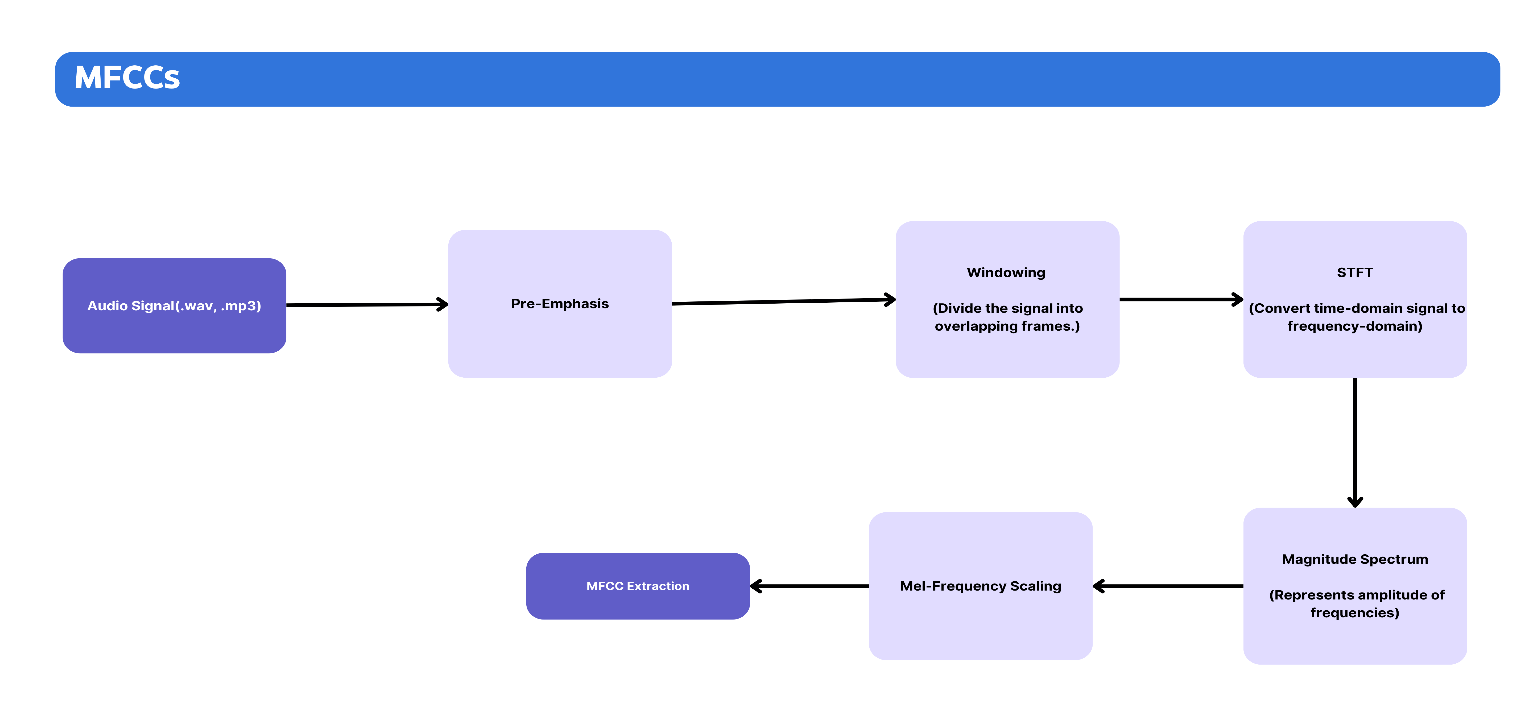
- MFCCs: Imagine the WAV file from the audio input is processed to extract MFCCs. These coefficients capture the power spectrum of the audio and are designed to mimic the human ear’s response to different frequencies. The result is a compact representation of the sound that highlights the important characteristics needed for speech recognition.
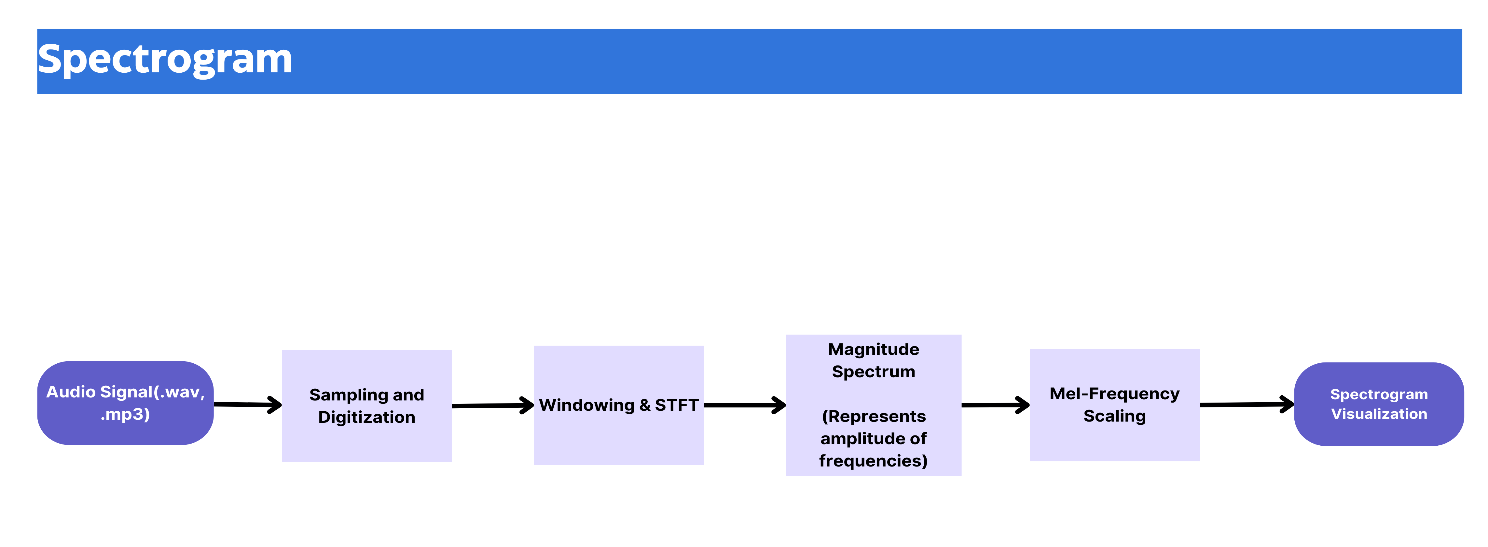
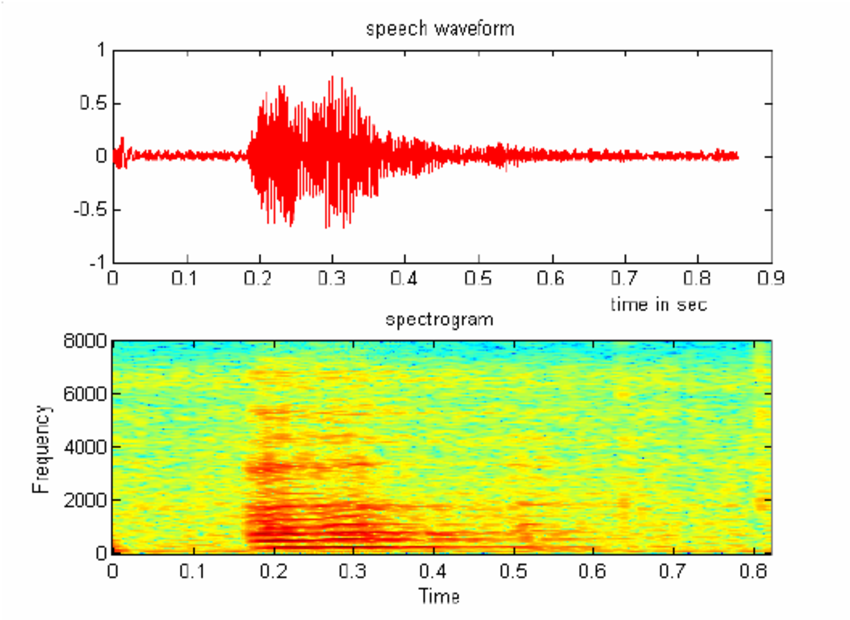
- Spectrogram: Another approach is to create a spectrogram, a visual representation of the audio signal over time. A spectrogram converts the audio into a 2D image, where the x-axis represents time, the y-axis represents frequency, and the color intensity represents amplitude. This image can then be fed into a model as if it were an image in an image recognition task.
- MFCCs: Imagine the WAV file from the audio input is processed to extract MFCCs. These coefficients capture the power spectrum of the audio and are designed to mimic the human ear’s response to different frequencies. The result is a compact representation of the sound that highlights the important characteristics needed for speech recognition.
Text Input
Handling text data is just as important as audio processing, especially during model training, which pairs audio with its corresponding text transcription.
- Example: If the audio clip contains the spoken phrase “I love machine learning,” the corresponding text input should match this exactly. The text should be clean and formatted, with no extra spaces or punctuation errors.
Text Processing Steps:
- Text Normalization:
- Overview: To maintain consistency, text normalization is used to convert all input into a uniform format. This process involves making text lowercase, removing special characters, and standardizing abbreviations or numbers.
- Example: The phrase “I Love Machine Learning!” would be normalized to “i love machine learning” to maintain consistency across the dataset.
- Tokenization:
- Overview: Tokenization is the process of splitting text into smaller units, typically words or subwords, that the model can process. This step is crucial for converting the text into a numerical format that the model can use.
- Example: The sentence “i love machine learning” could be tokenized into [“i”, “love”, “machine”, “learning”], each of which would be converted into a numerical representation.
- Sequence Alignment:
- Overview: When training a model, it’s important to ensure that the length of the text sequence aligns with the duration of the corresponding audio. This alignment is critical for effective model training.
- Example: For an audio file that is 3 seconds long, the text sequence should be concise enough that the model can learn to map each part of the audio to the corresponding text segment.
- Text Vectorization:
- Overview: After tokenization, the text data is converted into numerical vectors that can be fed into the neural network. Common methods include one-hot encoding, word embeddings (like Word2Vec), or character-level embeddings.
- Example: The word “machine” might be represented as a vector of real numbers that capture its semantic meaning in the context of the dataset.
- Text Normalization:
Model Architecture
Overview:The heart of an STT model lies in its architecture, which often combines different types of neural networks to process and understand the audio features.
- Convolutional Neural Networks (CNNs):
- Role: CNNs are adept at extracting spatial features from data. In the context of STT models, CNNs are typically used to process spectrograms or other 2D representations of the audio. They capture patterns such as changes in pitch or intensity over time.
- Details:
- Filters/Kernels: CNNs use multiple filters (or kernels) to slide over the spectrogram, detecting features like edges, textures, and patterns. Each filter extracts different features from the input image.
- Pooling Layers: After convolution, pooling layers (e.g., max pooling) reduce the spatial dimensions of the feature maps, keeping only the most important features. This reduces computational complexity and helps the model generalize better.
- Activation Functions: ReLU (Rectified Linear Unit) is commonly used to introduce non-linearity into the model. It helps the network learn complex patterns by applying the activation function to the output of the convolutional layers.
- Example: For a spectrogram of an audio clip, a CNN might detect patterns that correspond to phonetic units like vowels or consonants. The phoneme /a/ (as in the sound “ah”) produces a distinctive frequency pattern in the spectrogram. A particular filter in the CNN might become trained to detect this pattern because it is common across many examples of the phoneme /a/.
- Recurrent Neural Networks (RNNs) / Long Short-Term Memory (LSTM):
- Role: RNNs and LSTMs handle sequential data, maintaining a memory of previous inputs to understand context. LSTMs, a type of RNN, are particularly useful in speech recognition due to their ability to capture long-term dependencies.
- Details:
- Memory Cells: LSTMs have memory cells that store information for long periods. They include gates (input, output, and forget gates) that control the flow of information, allowing the model to retain or discard information based on its relevance.
- Sequence Processing: LSTMs process input sequences step-by-step, updating their memory cells with each new input. This helps them understand the temporal dependencies between different parts of the audio sequence.
- Example: For the sentence “I love machine learning,” the LSTM processes each word sequentially. It remembers the context of the phrase, which helps in distinguishing between “learning” and “leaning” based on the preceding words.
- Fully Connected Layers:
- Role: Fully connected layers (dense layers) integrate features extracted by CNNs and the temporal dependencies captured by LSTMs to produce the final output. They perform a final mapping from feature representations to the text space.
- Details:
- Dense Connections: Every neuron in a fully connected layer is connected to every neuron in the previous layer, allowing for complex interactions between features.
- Activation Functions: Typically, softmax is used in the final fully connected layer to convert the model’s output into a probability distribution over possible text tokens.
- Example: Imagine you’re writing a sentence using predictive text on your phone. The phone looks at the words you’ve typed so far and suggests the next word. This suggestion is made by predicting which word is most likely to come next based on everything that came before it.
In a speech-to-text model, fully connected layers work similarly. After the CNNs have analyzed the sound patterns, and the LSTMs have understood the sequence of those patterns over time, the fully connected layers take this information and make a final decision: they predict which word or sound comes next in the transcription.
For instance, if you say “Hello, how are,” the fully connected layer might predict that the next word is “you” based on how it learned language patterns from training. It’s like the brain of the model, making the final call on what word or sound is the most likely match for the speech input.
- Softmax Layer:
- Role: The softmax layer converts the output from the fully connected layers into probabilities for each possible text token. This helps the model select the most likely word at each step.
- Details:
- Probability Distribution: Softmax normalizes the output values into a probability distribution. Each value represents the probability of the corresponding token being the correct output.
- Selection: The token with the highest probability is chosen as the predicted word for that time step.
- Example: For a given time step in the sequence, if the softmax layer outputs probabilities for “I,” “love,” “machine,” and “learning” as 0.1, 0.3, 0.4, and 0.2 respectively, the model would predict “machine” as the most likely token.
- Decoding Methods:
- Role: Decoding methods transform the probabilistic outputs of the model into actual text sequences. Different methods balance between accuracy and computational efficiency.
- Details:
- Greedy Decoding: Selects the most probable token at each time step. It’s simple but might miss better sequences due to its myopic approach.
- Beam Search: Considers multiple possible sequences at each time step and maintains a beam of the most likely sequences. It balances between accuracy and computational complexity.
- Connectionist Temporal Classification (CTC):CTC is used for sequences where alignment between inputs and outputs is not explicitly provided. It allows the model to predict a probability distribution for each frame and then decode the sequence using a beam search or greedy approach.
- Example: For the sentence “I love machine learning,” beam search might explore various sequences like “I love machine learning” and “I love machine learning” to find the most accurate transcription, considering both the probabilities and the context.
Advanced Techniques
Attention Mechanisms and Transformers
As mentioned earlier, incorporating attention mechanisms can significantly enhance the performance of an STT model. These techniques allow the model to focus on relevant parts of the input sequence, improving transcription accuracy, especially for longer audio sequences.
For instance, Transformer models, which have revolutionized natural language processing, are now being applied to STT tasks. These models excel at capturing dependencies across the entire input sequence, offering state-of-the-art performance on various speech recognition benchmarks.
Future Enhancements
- Data Augmentation: Implementing data augmentation techniques, such as adding noise or pitch shifting, can help improve the model’s robustness.
- Transfer Learning: Pretrained models can be fine-tuned on your specific dataset, which can save time and improve accuracy.
- Real-Time Application: Optimizing the model for real-time processing involves reducing latency and computational requirements, making it suitable for deployment in applications like voice assistants.
Conclusion
Building a custom Speech-to-Text model involves understanding both the theory and practical aspects of audio processing and neural networks. From feature extraction to advanced model architectures, this guide has covered the essential steps to create your own STT model.
By following the steps outlined in this guide, you can implement a basic STT model and then explore more advanced techniques like attention mechanisms and data augmentation. Whether you’re aiming for a research project or a real-world application, the possibilities with STT technology are vast and exciting.
 Mastering Business Intelligence Dashboards: Excel Techniques You Need to Know
Mastering Business Intelligence Dashboards: Excel Techniques You Need to Know
 Turning Excel into a Scalable Business Tool: A Step-by-Step Guide
Turning Excel into a Scalable Business Tool: A Step-by-Step Guide
 The Psychology Behind Intuitive UX: How to Design for User Comfort
The Psychology Behind Intuitive UX: How to Design for User Comfort
 What Makes a Good MVP? Essential Tips for First-Time Founders
What Makes a Good MVP? Essential Tips for First-Time Founders
 How to Increase User Retention with Game Mechanics in Your App
How to Increase User Retention with Game Mechanics in Your App
 Excel Automation for Non-Technical Teams: A Beginner's Guide
Excel Automation for Non-Technical Teams: A Beginner's Guide
 How AI Is Transforming ERP Systems for SMEs
How AI Is Transforming ERP Systems for SMEs
 Why UX Is the Silent Salesperson in Every App
Why UX Is the Silent Salesperson in Every App
 Master Inventory Management with These VBA Tips and Tricks
Master Inventory Management with These VBA Tips and Tricks
 Timing Your Investment: The Key to Successful Business Automation
Timing Your Investment: The Key to Successful Business Automation